




Exploring bleeding edge experiments, oddities, new and bizarre dicoveries, and fact-checking conspiracy theories since 2008. No question is out of bounds and no topic is too strange for a deep dive.

# podcast
If you’re wondering when artificial intelligence will start destroying the world as we know it, wonder no more. That time is now.

# tech
Hollywood writers are once again on strike. Their goal? Nothing less than figuring out how humans and AI can coexist with runaway late-stage capitalism.

# tech
ChatGPT and its competitors are set to turn search, news, and social media into a complete dumpster fire.

# tech
In a legal and technical first, a robot lawyer is about to help a human defendant. Is it a good idea? And what happens next?

# tech
Generative AI is meant to help writers, artists, and coders. But it may be stealing from them first, creating a legal and ethical nightmare.

# tech
We keep seeing artificial intelligence do more and more impressive things. But the most impressive thing it can do next is to fit in our hands.

# tech
Writing, animation, and illustration, things that used to be uniquely human, are now being invaded by artificial intelligence. So, what’s next for creatives?

# tech
Don’t worry about the AI, worry about the humans training it, say researchers who found out how easy it is to turn machines evil.
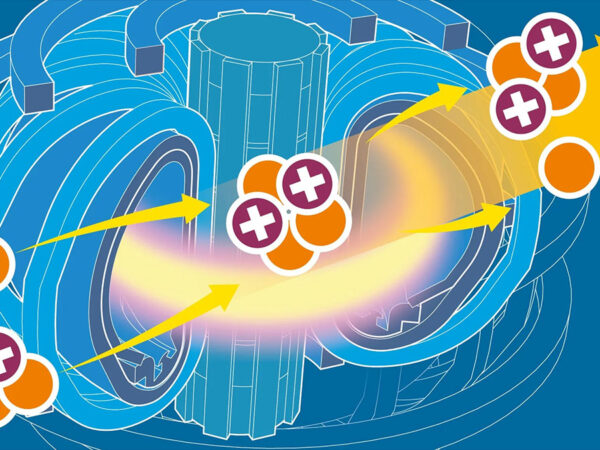
# science
Researchers trying to give the world a nearly limitless source of clean energy are getting a hand from an AI trained to fight against 100+ million degree plasma.

# astrobiology
A popular thought among experts thinking about alien life is that any intelligent life we discover in space will be artificial. But how realistic is this notion?