


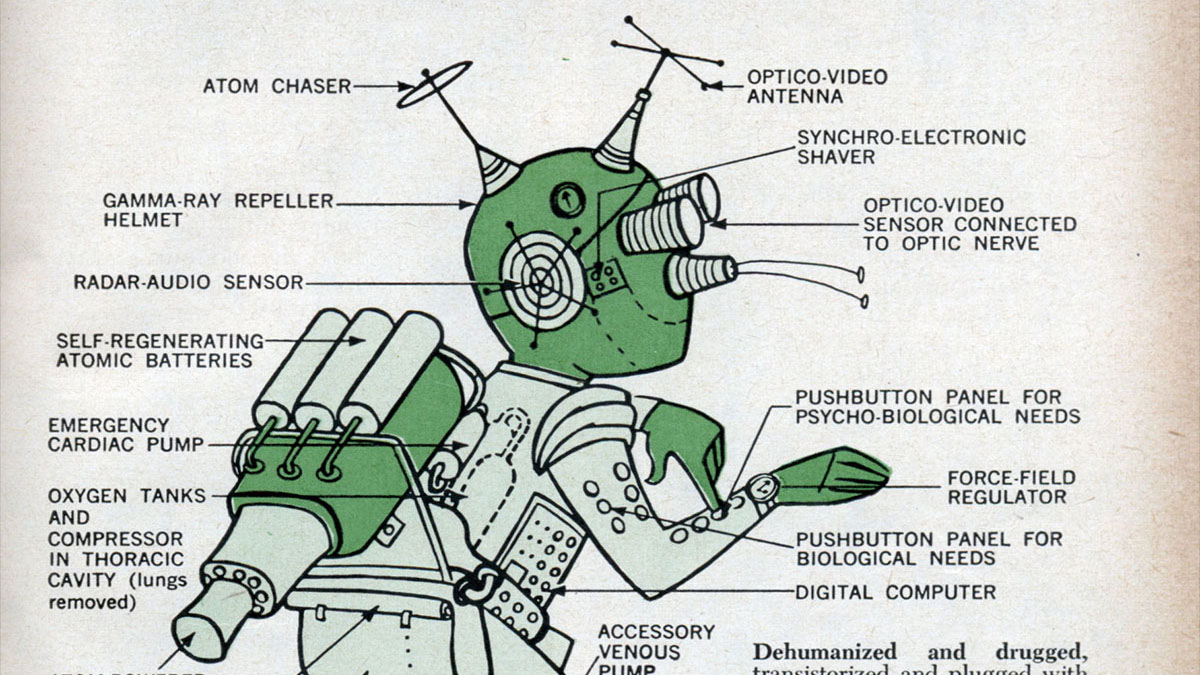



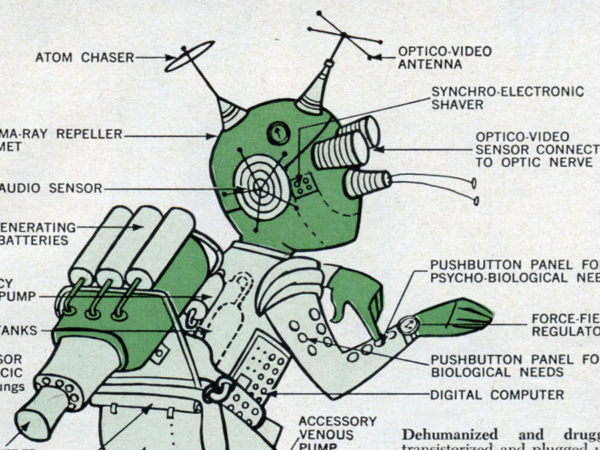






Exploring bleeding edge experiments, oddities, new and bizarre dicoveries, and fact-checking conspiracy theories since 2008. No question is out of bounds and no topic is too strange for a deep dive.

# oddities
Nine years on, conspiracy theories and questions are still flying around the fate of flight MH370. And they will never stop.

# science
Is time travel possible? What would happen if you did it? How would you do it? The answers to these questions are surprisingly complicated and weird.

# space
Space exploration is about to kick start a new era of nuclear energy and another chance to get the future right.

# oddities
Social media trolls declared “15-minute cities” to be a New World Order plan for open air mass prisons, derailing plans to make North American cities more livable yet again.

# tech
ChatGPT and its competitors are set to turn search, news, and social media into a complete dumpster fire.

# science
According to the news, our planet’s core has stopped spinning and will soon reverse. What’s really happening is a lot less exciting, but still pretty neat.

# health
One of scientists’ biggest fears about fungi and global warming is starting to slowly play out.

# tech
In a legal and technical first, a robot lawyer is about to help a human defendant. Is it a good idea? And what happens next?

# science
Despite what cranks, frauds, and their fans will tell you, scientists do listen to amateurs with good ideas, as two recent news stories demonstrate.

# science
Suburbs have long been the subject of consternation and ire from activists and urban planners, and research seems to agree with their critiques.