shhh… the internet may be watching
MIT's experiment in capturing how the web views you shows the limitations of parsing through massive, unstructured, loosely related data sets.


It knows when you are sleeping. It knows when you’re surfing porn. Well no, not really. To the vast networks which host all the information on the web and process the countless requests that keep the internet moving at the steady pace we’re now used to, you’re just a data point in a flood of bits and bytes. But the researchers at the MIT Media Labs decided to add some context to what your name means in the digital world to a machine tasked with categorizing all the existing and accessible information about you. Here’s how it sees me…

Lots of pretty colors there but what’s going on? The publicly available tool Personas does a search to see if it can find your name or something very closely matching it. It then picks up to 30 random snippets of text next or around a mention of you and analyzes keywords that would somehow describe who you are, putting the result in broad categories. The process isn’t exactly precise. In my case, it consistently kept confusing me with some fish caught by a guy named Greg, hence the large segment of sport-related keywords on my graph. Now I’m a person who harbors few delusions of grandeur, but getting e-upstaged by a halibut? That’s just brutal.
Overall, the output is somewhat like a psychic’s cold reading if the app can’t find accurate descriptions of you. All the tags and keywords that could build up your profile are put in very broad categories and combined into a representational graph which shows the relative occurrence of one category of keywords to the next. But wait just a second, what about people with plenty of references? Someone well known and frequently mentioned? Let’s think like software designers for a second. An algorithm that’s looking for descriptions of a celebrity must have more accurate snippets to choose from and hence, produce a more accurate graph if the person comes with a larger data bank. To find out if that really is the case, I did a little experiment and entered the names of a few well known skeptics and bloggers into the search box. After much thought in pretty shifting colors I set to a trance mix on my computer for a nerdy psychedelic effect, this is with what Personas came up…
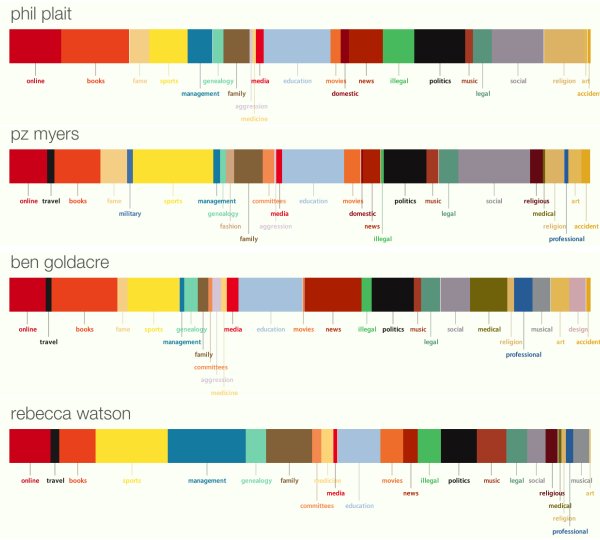
The queries it analyzed for PZ Myers, Phil Plait and Ben Goldacre were all right on the money and specifically talked about who they are, what they do and the issues with which they’re involved. Rebecca Watson, founder of Skepchick, didn’t fare so well however. Personas confused her with an energy secretary of an unidentified state which significantly skewed her graph. Of course the problem is that when all the graphs were finished, the overly broad categories don’t really tell you anything about the person, making an otherwise potentially fun toy for building up digital profiles little more than a graphical curiosity based on on far too few criteria. Though there is the vanity search factor involved as well because as you’re watching the whole thing come together, the more accurate quotes about you Personas chooses, the more people on the web are talking about you or your work, which is a good indication of your internet fame. Just don’t let it go to your CPU, ok?
[ thanks to social media expert Avi Joseph for the story tip ]






